Apache Gravitino 0.6.0 - First ASF release for Apache Gravitino™ (incubating)

This blog post will briefly introduce the new features and significant improvements. Keep reading to learn what the community has worked on and understand Gravitino’s use cases.
Introducing the unified RBAC model for Gravitino
Access control is a crucial feature for the enterprise use of a data catalog, providing users with unified and centralized authorization and authentication capabilities. This release introduces a role-based access control (RBAC) model in Gravitino to authorize different securable objects in a unified manner.
We use Privilege, SecurableObject, Role, User, and Group to define the permissions.

Privilege
Privilege defines the types of operations on different metadata objects, and is used to allow or deny a specific type of operation on a metadata object.
SecurableObject
SecurableObject binds multiple operation-specific types of privileges to a single metadata object.
Role
A Role is a collection of SecurableObjects, and a role represents multiple operation type permissions on multiple metadata objects.
User Users are granted one or multiple roles, and users have different operating privileges depending on their roles.
Group
To make it easier to grant a single permission to multiple users, we can add users to a group, and then grant one or more roles to that user group. This process allows all users belonging to that user group to have the permissions in those roles.
More importantly, the privileges authorized by the user in Gravitino will be pushed down to the underlying permission system. Currently, we support push permissions to Apache Ranger, others like IAM are under development.
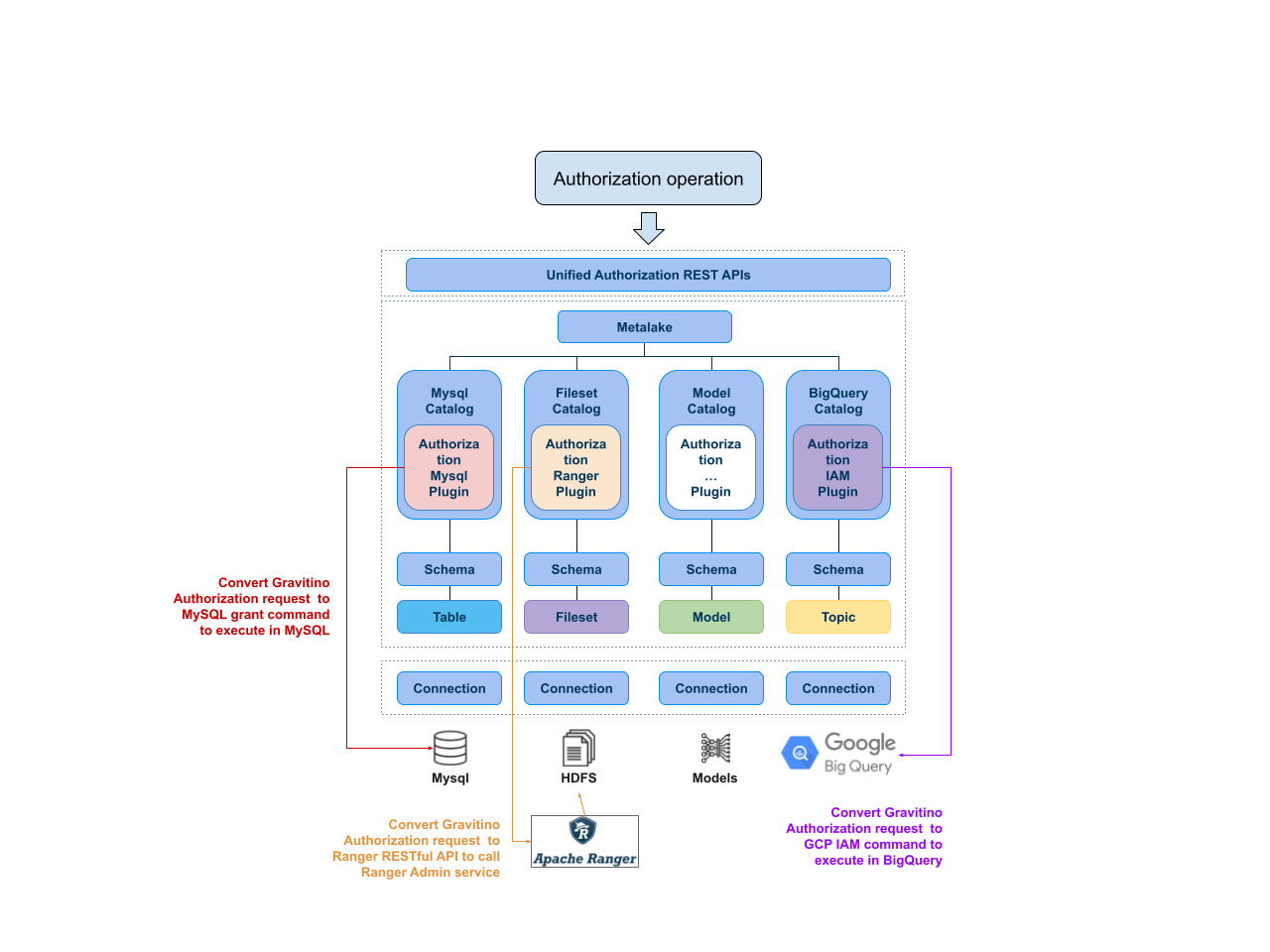
For more information about how our RBAC works, please check out our design document. To enable and use access control in Gravitino, please refer to the user document.
Our implementation of unified access control capability is still in the alpha stage, and we’re striving to add more features and make it stable as soon as possible, so please stay tuned.
Separation of the Iceberg REST catalog service
Apache Iceberg is a first-class citizen, and Gravitino has provided an embedded Iceberg REST catalog
service since version 0.3. We have seen the increased demands and adoption of Iceberg REST catalog
service as a standalone server. So, in version 0.6.0, we refactored the whole architecture and
modularized the Iceberg REST catalog service as a standalone service, allowing it to be deployed
with or without the Gravitino server. Besides the refactoring, we also bumped the supported version
to Iceberg 1.5.2, added support for S3 cloud storage, and now support the registerTable interface.
Iceberg REST catalog support is crucial to Gravitino, and modularization is just the first step. In future releases, we will add more features like cloud storage support and integrating Gravitino’s RBAC model, credential vending, etc.
To use the Gravitino Iceberg REST catalog service, please check our user document. The umbrella issue is #4058.
Tagging support
Tagging on metadata objects is useful for data discovery, classification, and data governance.
It can also be leveraged by query engines to provide tag-based access control. In Gravitino 0.6.0,
we introduce tag support users can add tags on metadata objects like CATALOG, SCHEMA, TABLE,
FILESET, and TOPIC. To know how our tag system is designed, please check out the
design document
and issue #3344. To use
tags in both REST API and Java SDK, please see how to manage tags.
Apache Flink Gravitino connector
As an open data catalog, we want to be able to support all query engines. Therefore, alongside Trino and Apache Spark, we have added Apache Flink as our newest supported query engine.
In 0.6.0, we added a new Flink Gravitino connector #1354 and supported querying Hive tables using Flink with Gravitino. Hive support is just our first step, we will continue to add more table support.
To know how to use the Flink Gravitino connector, please refer to our documentation.
Apache Paimon table management in Gravitino
Apache Paimon has become quite popular this year, and many companies use Paimon to build their streaming warehouse or lakehouse. To manage all the lakehouse tables in a unified manner, Gravitino has added Paimon table management in 0.6.0 #1129. Users can use our unified API to manage Paimon tables as well as other tables. To know more about how to manage Paimon tables, please refer to Lakehouse Paimon Catalog document.
Add Python GVFS support for fileset
In Gravitino 0.5, we added a Java Hadoop Compatible Filesystem (HCFS) support (GVFS) for fileset read/write in Gravitino. The provided Java GVFS can be used by query engines like Apache Spark to read/write data from files or folders. Although this works well in big data, AI development is largely dominated by Python, which can create an obstacle and hinder users from using Fileset with AI frameworks.
In 0.6.0, we followed the Python fsspec to provide a Python GVFS package that can be used by popular Python frameworks like Apache Arrow, Pandas, Ray, LlamaIndex, and more. You can check out Python GVFS document for more information.
Notable enhancements
Gravitino core
- Support catalog reload after a property is altered #2267.
- Deprecate KV store and add H2 support as embedded storage backend #3968.
Catalog relate
- Add API test catalog connection #4107.
- Improve the type system to support unknown types #3427.
- Add Kerberos support for fileset Hadoop catalog #3462.
- Add S3 support for Iceberg #4264.
- Support cloud and region property when creating catalog #3966.
- Support multiple Kerberos authentication for Hive catalog #3906.
- Unify the behavior of purge for all the catalogs #3685.
API and client
- Refactor Java and Python API for better user experience #3626.
- Add missing error handlers in Python client #4225.
All the resolved issues targeting the 0.6.0 release can be seen at https://github.com/apache/gravitino/issues?page=12&q=is%3Aissue+is%3Aclosed+label%3A0.6.0.
Overall
Apache Gravitino 0.6.0 is the first ASF release, we would like to show appreciation to the Gravitino community for their continued support and valuable contributions. Thanks to the feedback of our users, we are able to continue to innovate and build, so thanks to all those reading this!
To explore Gravitino 0.6.0 release, please check the documentation. Your feedback is invaluable to the community and the project.
Credits
This release acknowledges the hard work and dedication of all contributors who have helped make this release possible.
@1996fanrui @BSSsunny @FANNG1 @IamSaker @JinsYin @JosefinaOller @LanceHsun @LauraXia123 @Leonidas963 @LindaSummer @MukarramHaq @Naresh-kumar-Thodupunoori @Nishtha-Jain-1119 @SteNicholas @TEOTEO520 @Vishesh-Paliwal @ashwin1596 @bknbkn @caican00 @ch3yne @charliecheng630 @coolderli @danhuawang @diqiu50 @featherchen @hanwxx @ian910297 @jenish-thapa @jerqi @jerryshao @jingjia88 @jtao1 @justinmclean @kalencaya @khmgobe @kiratkumar47 @kohantikanath @kristopherkane @lsyulong @lw-yang @mchades @mygrsun @noidname01 @pan3793 @pravo23 @qqqttt123 @rich7420 @rohit-satya @shaofengshi @theoryxu @totalo @unknowntpo @xiaozcy @xloya @xunliu @yijhenlin @yuqi1129 @zhoukangcn @zivali
Apache Gravitino is an effort undergoing incubation at The Apache Software Foundation (ASF), sponsored by ASF Incubator. Incubation is required of all newly accepted projects until a further review indicates that the infrastructure, communications, and decision making process have stabilized in a manner consistent with other successful ASF projects. While incubation status is not necessarily a reflection of the completeness or stability of the code, it does indicate that the project has yet to be fully endorsed by the ASF.
Apache, Apache Iceberg, Apache Hive, Apache Fink, Apache Paimon and Apache Gravitino are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.